https://docs.oracle.com/cd/B19306_01/server.102/b14200/toc.htm
https://www.oracletutorial.com/
https://docs.oracle.com/cd/B19306_01/server.102/b14200/toc.htm
https://www.oracletutorial.com/
https://docs.oracle.com/en/database/oracle/oracle-database/19/adjsn/conditions-is-json-and-is-not-json.html#GUID-1B6CFFBE-85FE-41DD-BA14-DD1DE73EAB20
An important component for Analyst to summarize the data such as sales, profit, cost, and salary. Data Summarization is very helpful for Analyst to create a visualization, conclude findings, and report writing. In SQL, GROUP BY Clause is one of the tools to summarize or aggregate the data series. For example, sum up the daily sales and combine in a single quarter and show it to the senior management. Similarly, if you want to count how many employees in each department of the company. It groups the databases on the basis of one or more column and aggregates the results.
After Grouping the data, you can filter the grouped record using HAVING Clause. HAVING Clause returns the grouped records which match the given condition. You can also sort the grouped records using ORDER BY. ORDER BY used after GROUP BY on aggregated column.
In this tutorial, you are going to learn GROUP BY Clause in detail with relevant examples. Here is the list of topics that you will learn in this tutorial:
The GROUP BY Clause is utilized in SQL with the SELECT statement to organize similar data into groups. It combines the multiple records in single or more columns using some functions. Generally, these functions are aggregate functions such as min(),max(),avg(), count(), and sum() to combine into single or multiple columns. It uses the split-apply-combine strategy for data analysis.
split phase, It divides the groups with its values.apply phase, It applies the aggregate function and generates a single value.combiner phase, It combines the groups with single values into a single value.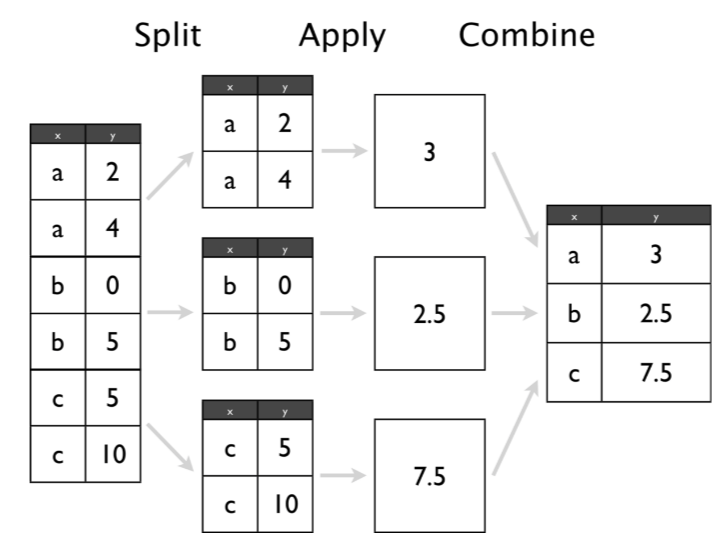 Image source
Image sourcePoints to Remember:
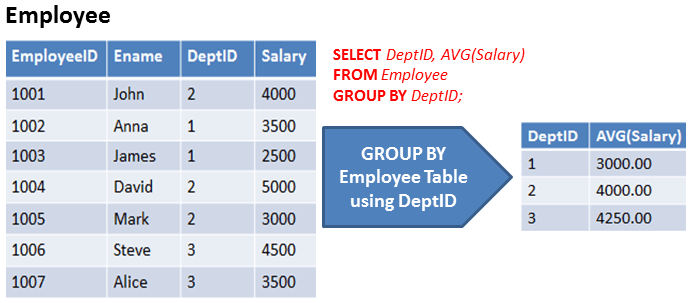
In above example, Table is grouped based on the DeptID column and Salary is aggregated department-wise.
HAVING Clause utilized in SQL as a conditional Clause with GROUP BY Clause. This conditional clause returns rows where aggregate function results matched with given conditions only. It added in the SQL because WHERE Clause cannot be combined with aggregate results, so it has a different purpose. The primary purpose of the WHERE Clause is to deal with non-aggregated or individual records.
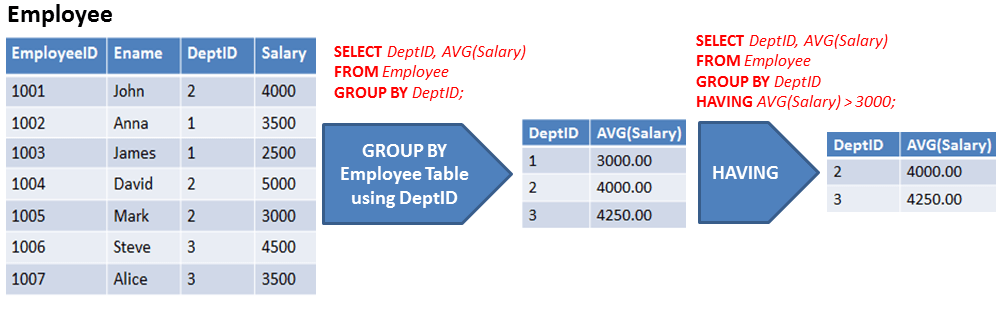
In above example, Table is grouped based on DeptID column and these grouped rows filtered using HAVING Clause with condition AVG(Salary) > 3000.
Aggregate functions used to combine the result of a group into a single such as COUNT, MAX, MIN, AVG, SUM, STDDEV, and VARIANCE. These functions also known as multiple-row functions.
SUM(): Returns the sum or total of each group.COUNT(): Returns the number of rows of each group.AVG(): Returns the average and mean of each group.MIN(): Returns the minimum value of each group.MAX(): Returns the minimum value of each group. Image Source
Image SourceThe normalized relational database breaks down the complex table into small tables, which helps you to eliminate the data redundancy, inconsistency and ensure there is no loss of information. Normalized tables require joining data from multiple tables.
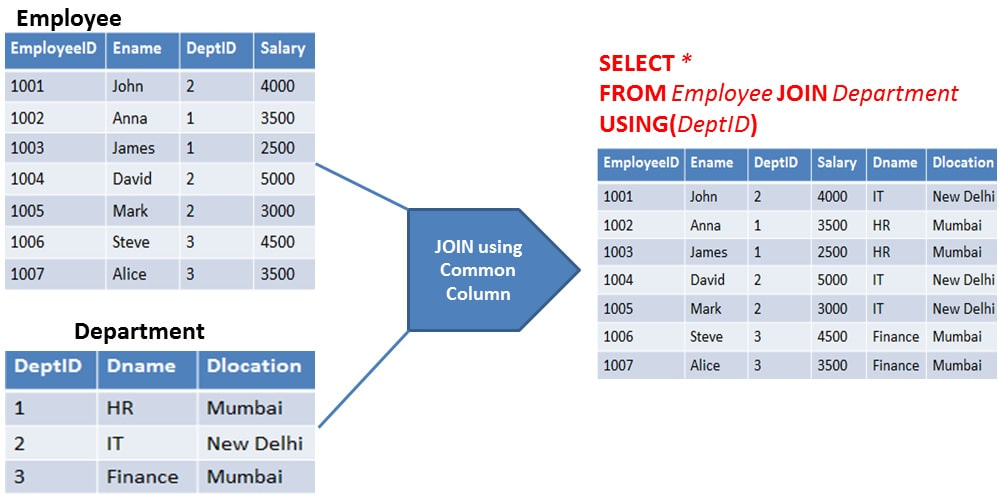
In above example, Employee and Department are joined using the common column DeptID.
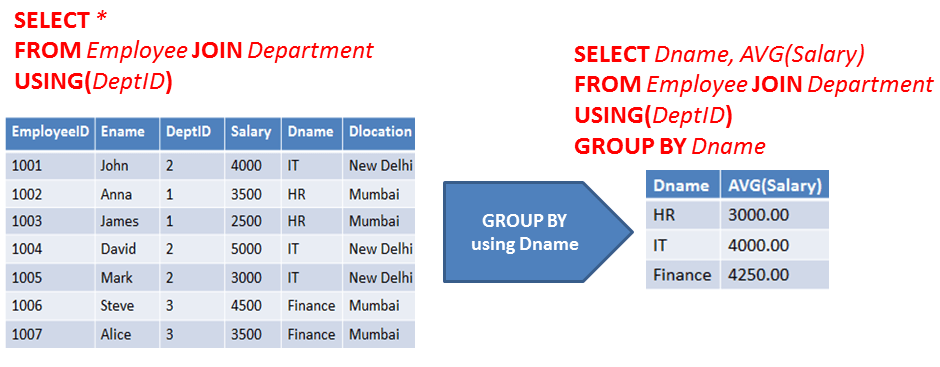
In the above example, JOIN and GROUP BY both clauses used together in a single query. After joining both tables(Employee and Department), joined table grouped by Department name.
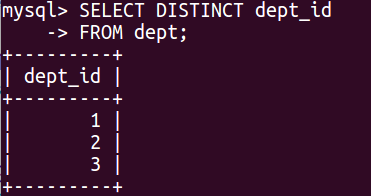
DISTINCT returns the unique values present in the column while GROUP BY returns unique/distinct items with the aggregate resultant column. In the following example you can see the DISTINCT values in the dept table.
ORDER BY returns sorted items in ascending and descending order while GROUP BY returns unique items with the aggregate resultant column. In the following example, you can see the ORDER BY or sorted salary table.
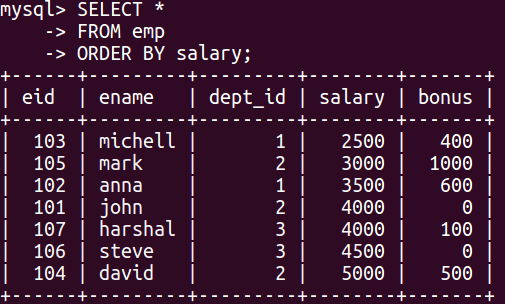
Table Name: Books
Columns: ISBN, Title, Publication Date, Price, Publisher
Write SQL queries for the following statements and share your answers in comments:
Source: This Assignment is inspired from the book "Oracle 11g SQL" by John Casteel.
Congratulations, you have made it to the end of this tutorial!
In this tutorial, you have covered a lot of details about the GROUP BY and HAVING Clause. You have learned what the GROUP BY and HAVING Clause are with examples, Comparison between HAVING and WHERE Clause in SQL, GROUP BY with JOIN, and GROUP BY Comparison with DISTINCT and ORDER BY. In the last section, you have a Hands-on practice assignment to assess your knowledge.
Hopefully, you can now utilize GROUP BY and HAVING Clause concept to analyze your own datasets. Thanks for reading this tutorial!
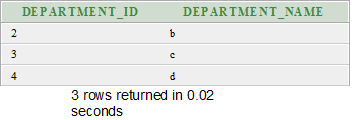
Anti-join is used to make the queries run faster. It is a very powerful SQL construct Oracle offers for faster queries.
Anti-join between two tables returns rows from the first table where no matches are found in the second table. It is opposite of a semi-join. An anti-join returns one copy of each row in the first table for which no match is found.
Anti-joins are written using the NOT EXISTS or NOT IN constructs.
Example
Let's take two tables "departments" and "customer"
Departments table
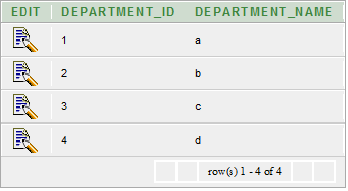
Customer table
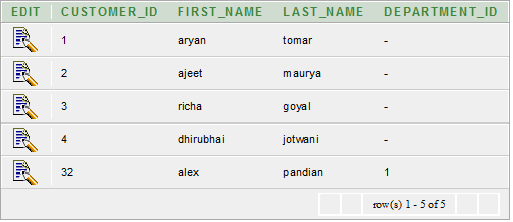
Execute this query
Output
regexp_substr tipsOracle Database Tips by Donald BurlesonMay 25, 2016 |
Question: What does the regexp_substr operator do? Can you show an example of using regexp_substr?
Answer: The regexp_substr operator searches for a sub-string within a string.
The REGEXP_SUBSTR function is the advanced version of the classic SUBSTR function, allowing us to search for strings based on a regular expression pattern. This function returns a portion of the source string based on the search pattern but not its position. The substring returned by this function can be either of VARCHAR2 or CLOB data type in the same character set as that of the input source string.
The prototype of the REGEXP_SUBSTR function is shown below,
REGEXP_SUBSTR(<Source_string>, <Search_pattern>[, <Start_position>[, <Match_occurrence>[, <Match_modifiers>]]])
· Source_string: The string to be searched for.
· Search_pattern: The regular expression pattern that is to be searched for in the source string. This can be a combination of the POSIX and the Perl-influenced metacharacters mentioned in the above section.
· Start_position: This is an optional parameter. This determines the position in the source string where the search starts. By default, it is 1, which is the starting position of the source string.
· Match_occurrence: This is an optional parameter. This determines the occurrence of the search pattern. By default, it is 1, which is the first appearance of the search pattern in the string.
· Match_modifiers: This is an optional parameter. This parameter allows us to modify, the matching behavior of the function. The valid range of options is mentioned in the Pattern Matching Modifiers section explained above.
The below shown example prints out the statement word by word for its corresponding match occurrence value.
SELECT regexp_substr('This is an interesting chapter','[[:alpha:]]+',1,1) regexp_substr
FROM dual;
For the match occurrence value 1 (Fourth parameter),
Result:
This
Using the CONNECT BY LEVEL clause, all the words from the source string can be displayed for all possible the match occurrence values using the LEVEL keyword as the fourth parameter in the above query. The total number of match occurrences is found by counting the number of spaces in the input string and adding 1 to it using the REGEXP_COUNT function.
SELECT regexp_substr('This is an interesting chapter', '[[:alpha:]]+', 1, level) regexp_substr
FROM dual
CONNECT BY level<=regexp_count('This is an interesting chapter',' ')+1;
Result:
This
is
an
interesting
chapter
The below statement separates the string into multiple chunks by the separator “,†which is mentioned in the search pattern. The search pattern “[ ^ , ] +†negates the “,†character and searches for the characters other than comma followed by a non-comma character in the source string.
SELECT regexp_substr('Apple,Orange,Mango,Grapes','[^,]+',1,1) regexp_substr
FROM dual;
For the match occurrence value 1 (Fourth parameter),
Result:
Apple
With the help of the CONNECT BY LEVEL clause, all the chunks of the source string can be displayed by using the LEVEL keyword as the match occurrence. Here, the CONNECT BY LEVEL clause generates the rows equal to the number of commas +1 in the source string.
SELECT regexp_substr('Apple,Orange,Mango,Grapes','[^,]+',1,level) regexp_substr
FROM dual
CONNECT BY level<=regexp_count('Apple,Orange,Mango,Grapes',',')+1;
Result:
Apple
Orange
Mango
Grapes
The below snippet takes out the website’s name from a list of web pages. Here, the first part of the search pattern checks for a series of alphabets followed by a DOT character ([[:alpha:]]+\.) which searches and finds the match from the string as “www.â€. Then the rest of the search pattern ([a-zA-Z0-9._-]+) looks for a series of characters which can be an alphabet, number, DOT character, underscore and a hyphen. When a character other than listed in the previous statement is found, the search process is stopped. In this example, the domain names with their extension “domain-name.comâ€, “domain_name.eduâ€, “domain.name.org†are selected as the next character is a front slash (/).
WITH t AS
(SELECT 'https://www.domain-name.com/page1.html' col FROM dual
UNION ALL
SELECT 'http://www.domain_name.edu/page_2.htm' FROM dual
UNION ALL
SELECT 'http://www.domain.name.org/page?3.htm' FROM dual
)
SELECT regexp_substr(col,'[[:alpha:]]+\.[a-zA-Z0-9._-]+') FROM t;
Result:
www.domain-name.com
www.domain_name.edu
www.domain.name.org
In the below example, the source string has a Newline character “chr(10)†concatenated between the three names in the WITH clause. The search pattern (^[[:alpha:]]+) looks for the string starting with an alphabet until it finds another non-matching character (Non-alphabet), in this case, a Newline character.
This query is executed for three different match occurrences as shown below,
WITH t AS
(SELECT 'Aamir'||chr(10)||'Ashok'||chr(10)||'Ashley' col FROM dual
)
SELECT REGEXP_SUBSTR(col, '^[[:alpha:]]+',1,1)regexp_substr1,
REGEXP_SUBSTR(col, '^[[:alpha:]]+',1,2)regexp_substr2,
REGEXP_SUBSTR(col, '^[[:alpha:]]+',1,3)regexp_substr3
FROM t;
Result:
Aamir Null Null
However, when the match modifier is changed to multiline mode by using the literal m as the match modifier parameter, the same query considers the Newline character as a different line and assumes that these three names are in different lines and processes it.
When this query is executed for the same match occurrences as above,
WITH t AS
(SELECT 'Aamir'||chr(10)||'Ashok'||chr(10)||'Ashley' col FROM dual
)
SELECT REGEXP_SUBSTR(col, '^[[:alpha:]]+',1,1,'m')regexp_substr1,
REGEXP_SUBSTR(col, '^[[:alpha:]]+',1,2,'m')regexp_substr2,
REGEXP_SUBSTR(col, '^[[:alpha:]]+',1,3,'m')regexp_substr3
FROM t;
Result:
Aamir Ashok Ashley
Oracle 10g introduced regular expression functions in SQL with the functions REGEXP_SUBSTR, REGEXP_REPLACE, REGEXP_INSTR and REGEXP_LIKE. Oracle 11g extends the set of available expressions with REGEXP_COUNT.
SELECT
ENAME,
REGEXP_SUBSTR(ENAME,'DAM') SUBSTR,
REGEXP_INSTR(ENAME, 'T') INSTR,
REGEXP_REPLACE(ENAME,'AM','@') REPLACE,
REGEXP_COUNT(ENAME, 'A') COUNT
FROM
EMP
WHERE
REGEXP_LIKE(ENAME,'S');
ENAME SUBSTR INSTR REPLACE COUNT
---------- ---------- ---------- ---------- ----------
SMITH 4 SMITH 0
JONES 0 JONES 0
SCOTT 4 SCOTT 0
ADAMS DAM 0 AD@S 2
JAMES 0 J@ES 1
REGEXP_SUBSTR returns the substring DAM if found, REGEXP_INSTR returns the position of the first 'T', REGEXP_REPLACE replaces the strings 'AM' with '@' and REGEXP_COUNT counts the occurrences of 'A'. REGEXP_LIKE returns the strings that contain the pattern 'S'.
SELECT
REGEXP_SUBSTR('Programming','[[:alpha:]]+',1,2)
FROM
DUAL;
REGEXP
------
Oracle
'[[:alpha:]]' is a POSIX regular expression that matches any letter. The second set of consecutive word characters is returned. The '+' specifies that the number of characters to be matched is one or more. '.' matches exactly one character; '.?' matches zero or one character; '.*' match zero, one or more character; '.+' matches one or more character; '.{3}' matches exactly three characters; '.{4,6}' matches 4, 5 or 6 characters; '.{7,}' matches 7 or more characters. The third argument is the starting position. The default 1 means the pattern will be searched from the beginning of the substring. The fourth argument in 11g represents the occurrence of the substring.
SELECT
REGEXP_SUBSTR('Programming','\w+',1,2)
FROM
DUAL;
REGEXP
------
Oracle
Oracle 10gR2 introduced Perl-influenced regular expressions. '\w' represents any letter, number and the underscore. Unfortunately, in comparison to the old-style approach with INSTR and SUBSTR, the 10g regular expressions perform poorly.
SET TIMING ON
DECLARE
X VARCHAR2(40);
BEGIN
FOR I IN 1..10000000 LOOP
X := 'Programming';
X := SUBSTR(X,
INSTR(X, ' ')+1,
INSTR(X, ' ', 1,2)-INSTR(X, ' ')-1);
END LOOP;
END;
/
PL/SQL procedure successfully completed.
Elapsed: 00:00:20.40
SET TIMING ON
DECLARE
X VARCHAR2(40);
BEGIN
FOR I IN 1..10000000 LOOP
X := 'Programming';
X := REGEXP_SUBSTR(X,'\w+',1,2);
END LOOP;
END;
/
PL/SQL procedure successfully completed.
Elapsed: 00:02:10.82
REPLACE replaces all occurrence of a string. REGEXP_REPLACE has the same behavior by default, but when the fifth parameter, OCCURRENCE, is set to a value greater than zero, the substitution is not global.
SELECT
REGEXP_REPLACE
(
'Programming',
'([[:alpha:]]+)[[:space:]]([[:alpha:]]+)',
'\2: \1',
1,
1
)
FROM
DUAL;
REGEXP_REPLACE('ADVANCEDORACLESQ
--------------------------------
Oracle: Advanced SQL Programming
The search pattern contains a group of one or more alphabetic characters, followed by a space, then followed by a group of one or more alphabetic characters. This pattern is present more than once in the string, but only the first occurrence is affected. The replace pattern contains a reference to the second word, followed by a column and a space, followed by the first string.
SELECT
REGEXP_SUBSTR
(
'Programming',
'(\w).*?\1',
1,
1,
'i'
)
FROM
DUAL;
REGE
----
Adva
The search pattern contains any alphabetic character followed by a non-greedy number of characters followed by the same character as in the group. The search starts at the character one and looks for the first match of the pattern. The modifier 'i' indicates a case insensitive search. Non-greedy expressions appeared in 10gR2. The difference between a non-greedy expression like '.*?', '.+?', '.??', '.{2}?', '.{3,5}?' or '.{6,}?' and a greedy expression like '.*', '.+', '.?', '.{2}', '.{3,5}' or '.{6,}' is that the non-greedy searches for the smallest possible string and the greedy for the largest possible string.
SELECT
REGEXP_SUBSTR
(
'Oracle',
'.{2,4}?'
) NON_GREEDY,
REGEXP_SUBSTR
(
'Oracle',
'.{2,4}'
) GREEDY
FROM
DUAL;
NON_GREEDY GREEDY
---------- ------
Or Orac
Both patterns select from two to four characters. In this case, it could be 'Or', 'Ora' or 'Orac'. The non-greedy pattern returns two and the greedy four:
SELECT
ENAME,
REGEXP_SUBSTR(ENAME,JAMES ES JAMES
FORD RD
MILLER M'^K') "^K",
REGEXP_SUBSTR(ENAME,'T$') "T$",
REGEXP_SUBSTR(ENAME,'^[ABC]') "^[ABC]",
REGEXP_SUBSTR(ENAME,'^.?M') "^.?M",
REGEXP_SUBSTR(ENAME,'(RD|ES)$') "(RD|ES)$",
REGEXP_SUBSTR(ENAME,'(..R){2}') "(..R){2}",
REGEXP_SUBSTR(ENAME,'^.{4}[^A-E]') "^.{4}[^A-E]"
FROM
EMP;
ENAME ^K T$ ^[ABC] ^.?M (RD|ES)$ (..R){2} ^.{4}[^A-E
---------- -- -- ------ ---- -------- -------- ----------
SMITH SM SMITH
ALLEN A ALLEN
WARD RD
JONES ES JONES
MARTIN M MARTI
BLAKE B
CLARK C CLARK
SCOTT T SCOTT
KING K
TURNER TURNER
ADAMS A ADAMS
The function REGEXP_SUBSTR matches ENAME to a pattern and returns the matched string. The first pattern checks if the name starts with 'K', the second checks if it ends with 'T', the third checks if it starts with A, B or C, the fourth checks if the string start with one or zero characters followed by M (which means the first or second character is a 'M'), the fifth checks if it ends with either ES or RD, the sixth checks if the pattern ?one character + one character + the letter R? is found twice consecutively and the last pattern checks if the fifth character (the character following 4 characters at the beginning of the string) is not in the range A-E. Note that KING is not matched because the fifth character is not a character different from A-E. To test a string less than five characters, the pattern ^.{1,4}$ could be used.
| Oracle Database 10g Release 1 | 10.1.0.2 | 2003 | 10.1.0.5 | February 2006 | Automated Database Management, Automatic Database Diagnostic Monitor, Grid infrastructure, Oracle ASM, Flashback Database |
| Oracle Database 10g Release 2 | 10.2.0.1 | July 2005 [16] | 10.2.0.5 | April 2010 | Real Application Testing, Database Vault, Online Indexing, Advanced Compression, Data Guard Fast-Start Failover, Transparent Data Encryption |
| Oracle Database 11g Release 1 | 11.1.0.6 | September 2007 | 11.1.0.7 | September 2008 | Active Data Guard, Secure Files, Exadata |
| Oracle Database 11g Release 2 | 11.2.0.1 | September 2009 [17] | 11.2.0.4 | August 2013 | Edition Based Redefinition, Data Redaction, Hybrid Columnar Compression, Cluster File System, Golden Gate Replication, Database Appliance |
| Oracle Database 12c Release 1 | 12.1.0.1 | July 2013 [18] | 12.1.0.2 | July 2014 | Multitenant architecture, In-Memory Column Store, Native JSON, SQL Pattern Matching, Database Cloud Service |
| Oracle Database 12c Release 2 | 12.2.0.1 | September 2016 (cloud) March 2017 (on-prem) | Native Sharding, Zero Data Loss Recovery Appliance, Exadata Cloud Service, Cloud at Customer | ||
| Oracle Database 18c | 18.1.0 // 12.2.0.2 | February 2018 (Cloud & Engineered Systems: 18.1.0)[19] July 2018 (on-prem: 18.3.0)[20] | Polymorphic Table Functions, Active Directory Integration | ||
| Oracle Database 19c | 19.1.0 // 12.2.0.3 | February 2019 (Exadata)[21] April 2019 (Linux and other platforms)[22] June 2019 (cloud) August 2019 (most recent patch set)[23] |